Jason Jingzhou Liu
Email: liujason [at] cmu [dot] edu
|
I am a second-year Robotics PhD student at Carnegie Mellon University in the School of Computer Science. I am advised by Deepak Pathak and Ruslan Salakhutdinov, working on robot learning and dexterous manipulation. I graduated from Engineering Science at the University of Toronto, where I received my B.ASc. Previously, I worked with Florian Shkurti at the Robot Vision & Learning Lab. I also worked on simulation and robot learning research at NVIDIA, collaborating with Ankur Handa, Karl Van Wyk, and Nathan Ratliff. Feel free to contact me via email at liujason [at] cmu [dot] edu! |

|
ResearchI am interested in building robotic systems capable of performing dexterous, robust, human-like skills that can generalize to unstructrued and diverse environemnts. My research focuses on robot learning for manipulation and perception with an emphasis on sim-to-real. Representative papers are highlighted. |
|
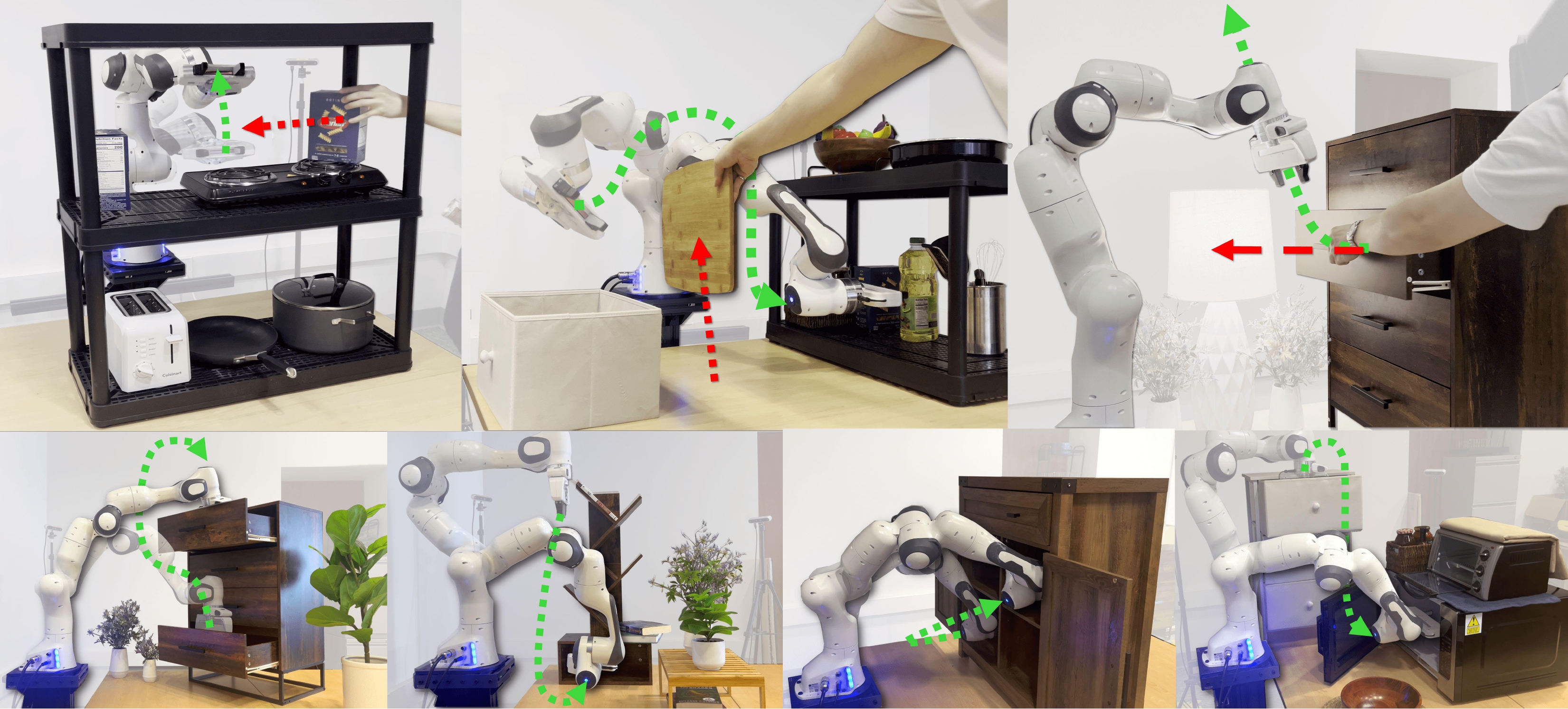
Deep Reactive Policy: Learning Reactive Manipulator Motion Planning for Dynamic Environments
Jiahui Yang*, Jason Jingzhou Liu*, Yulong Li, Youssef Khaky, Kenneth Shaw, Deepak Pathak CoRL 2025 Best Paper Award at LeaPRiDE Workshop
website
|
abstract
|
bibtex
|
arXiv
Generating collision-free motion in dynamic, partially observable environments is a fundamental challenge for robotic manipulators. Classical motion planners can compute globally optimal trajectories but require full environment knowledge and are typically too slow for dynamic scenes. Neural motion policies offer a promising alternative by operating in closed-loop directly on raw sensory inputs but often struggle to generalize in complex or dynamic settings. We propose Deep Reactive Policy (DRP), a visuo-motor neural motion policy designed for reactive motion generation in diverse dynamic environments, operating directly on point cloud sensory input. At its core is IMPACT, a transformer-based neural motion policy pretrained on 10 million generated expert trajectories across diverse simulation scenarios. We further improve IMPACT's static obstacle avoidance through iterative student-teacher finetuning. We additionally enhance the policy's dynamic obstacle avoidance at inference time using DCP-RMP, a locally reactive goal-proposal module. We evaluate DRP on challenging tasks featuring cluttered scenes, dynamic moving obstacles, and goal obstructions. DRP achieves strong generalization, outperforming prior classical and neural methods in success rate across both simulated and real-world settings. We will release the dataset, simulation environments, and trained models upon acceptance. |

|
DexWild: Dexterous Human Interactions for In-the-Wild Robot Policies
Tony Tao*, Mohan Kumar Srirama*, Jason Jingzhou Liu, Kenneth Shaw, Deepak Pathak RSS 2025 (Oral) Best Paper Award at EgoAct Workshop
website
|
abstract
|
bibtex
|
arXiv
|
code
Large-scale, diverse robot datasets have emerged as a promising path toward enabling dexterous manipulation policies to generalize to novel environments, but acquiring such datasets presents many challenges. While teleoperation provides high-fidelity datasets, its high cost limits its scalability. Instead, what if people could use their own hands, just as they do in everyday life, to collect data? In DexWild, a diverse team of data collectors uses their hands to collect hours of interactions across a multitude of environments and objects. To record this data, we create DexWild-System, a low-cost, mobile, and easy-to-use device. The DexWild learning framework co-trains on both human and robot demonstrations, leading to improved performance compared to training on each dataset individually. This combination results in robust robot policies capable of generalizing to novel environments, tasks, and embodiments with minimal additional robot-specific data. Experimental results demonstrate that DexWild significantly improves performance, achieving a 68.5% success rate in unseen environments-nearly four times higher than policies trained with robot data only-and offering 5.8x better cross-embodiment generalization. |
|
FACTR: Force-Attending Curriculum Training
for Contact-Rich Policy Learning
Jason Jingzhou Liu*, Yulong Li*, Kenneth Shaw, Tony Tao, Ruslan Salakhutdinov, Deepak Pathak RSS 2025 (Oral)
website
|
abstract
|
bibtex
|
arXiv
|
code
Many contact-rich tasks humans perform, such as box pickup or rolling dough, rely on force feedback for reliable execution. However, this force information, which is readily available in most robot arms, is not commonly used in teleoperation and policy learning. Consequently, robot behavior is often limited to quasi-static kinematic tasks that do not require intricate force-feedback. In this paper, we first present a low-cost, intuitive, bilateral teleoperation setup that relays external forces of the follower arm back to the teacher arm, facilitating data collection for complex, contact-rich tasks. We then introduce FACTR, a policy learning method that employs a curriculum which corrupts the visual input with decreasing intensity throughout training. The curriculum prevents our transformer-based policy from over-fitting to the visual input and guides the policy to properly attend to the force modality. We demonstrate that by fully utilizing the force information, our method significantly improves generalization to unseen objects by 43% compared to baseline approaches without a curriculum. |

|
Synthetica: Large Scale Synthetic Data Generation for Robot
Perception
Ritvik Singh, Jingzhou Liu, Karl Van Wyk, Yu-Wei Chao, Jean-Francois Lafleche, Florian Shkurti, Nathan Ratliff, Ankur Handa IROS 2025 (Oral)
website
|
abstract
|
bibtex
|
arXiv
Vision-based object detectors are a crucial basis for robotics applications as they provide valuable information about object localisa- tion in the environment. These need to ensure high reliability in differ- ent lighting conditions, occlusions, and visual artifacts, all while running in real-time. Collecting and annotating real-world data for these net- works is prohibitively time consuming and costly, especially for custom assets, such as industrial objects, making it untenable for generalization to in-the-wild scenarios. To this end, we present Synthetica, a method for large-scale synthetic data generation for training robust state estimators. This paper focuses on the task of object detection, an important problem which can serve as the front-end for most state estimation problems, such as pose estimation. Leveraging data from a photorealistic ray-tracing ren- derer, we scale up data generation, generating 2.7 million images, to train highly accurate real-time detection transformers. We present a collection of rendering randomization and training-time data augmentation tech- niques conducive to robust sim-to-real performance for vision tasks. We demonstrate state-of-the-art performance on the task of object detec- tion while having detectors that run at 50–100Hz which is 9 times faster than the prior SOTA. We further demonstrate the usefulness of our training methodology for robotics applications by showcasing a pipeline for use in the real world with custom objects for which there do not exist prior datasets. Our work highlights the importance of scaling syn- thetic data generation for robust sim-to-real transfer while achieving the fastest real-time inference speeds. |

|
ORBIT-Surgical: An Open-Simulation Framework for Accelerated Learning
Environments in Surgical Autonomy
Qinxi Yu*, Masoud Moghani*, Karthik Dharmarajan, Vincent Schorp, William Chung-Ho Panitch, Jingzhou Liu, Kush Hari, Huang Huang, Mayank Mittal, Ken Goldberg, Animesh Garg ICRA 2024
website
|
abstract
|
bibtex
|
arXiv
Physics-based simulations have accelerated progress in robot learning for driving, manipulation, and locomotion. Yet, a fast, accurate, and robust surgical simulation environment remains a challenge. In this paper, we present ORBIT-Surgical, a physics-based surgical robot simulation framework with photorealistic rendering in NVIDIA Omniverse. We provide 14 benchmark surgical tasks for the da Vinci Research Kit (dVRK) and Smart Tissue Autonomous Robot (STAR) which represent common subtasks in surgical training. ORBIT-Surgical leverages GPU parallelization to train reinforcement learning and imitation learning algorithms to facilitate study of robot learning to augment human surgical skills. ORBIT-Surgical also facilitates realistic synthetic data generation for active perception tasks. We demonstrate ORBIT-Surgical sim-to-real transfer of learned policies onto a physical dVRK robot. |
|
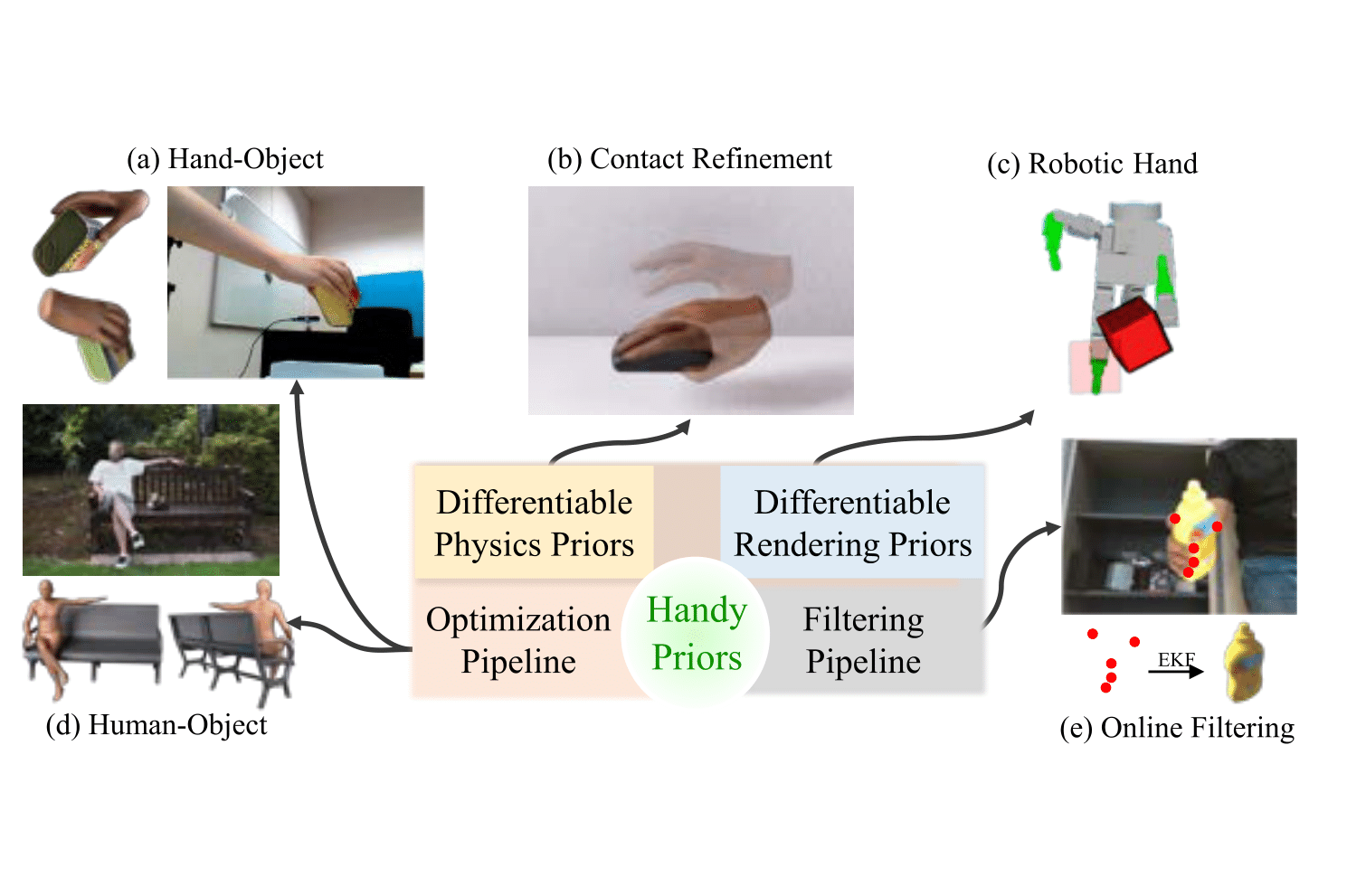
HandyPriors: Physically Consistent Perception of Hand-Object Interactions
with Differentiable Priors
Shutong Zhang*, Yiling Qiao*, Guanglei Zhu*, Eric Heiden, Dylan Turpin, Jingzhou Liu, Ming Lin, Miles Macklin, Animesh Garg ICRA 2024
website
|
abstract
|
bibtex
|
arXiv
Various heuristic objectives for modeling handobject interaction have been proposed in past work. However, due to the lack of a cohesive framework, these objectives often possess a narrow scope of applicability and are limited by their efficiency or accuracy. In this paper, we propose HANDYPRIORS, a unified and general pipeline for pose estimation in human-object interaction scenes by leveraging recent advances in differentiable physics and rendering. Our approach employs rendering priors to align with input images and segmentation masks along with physics priors to mitigate penetration and relative-sliding across frames. Furthermore, we present two alternatives for hand and object pose estimation. The optimization-based pose estimation achieves higher accuracy, while the filtering-based tracking, which utilizes the differentiable priors as dynamics and observation models, executes faster. We demonstrate that HANDYPRIORS attains comparable or superior results in the pose estimation task, and that the differentiable physics module can predict contact information for pose refinement. We also show that our approach generalizes to perception tasks, including robotic hand manipulation and human-object pose estimation in the wild. |

|
DeXtreme: Transfer of Agile In-Hand Manipulation from Simulation to
Reality
Ankur Handa*, Arthur Allshire*, Viktor Makoviychuk*, Aleksei Petrenko*, Ritvik Singh*, Jingzhou Liu*, Denys Makoviichuk, Karl Van Wyk, Alexander Zhurkevich, Balakumar Sundaralingam, Yashraj Narang, Jean-Francois Lafleche, Dieter Fox, Gavriel State ICRA 2023
website
|
abstract
|
bibtex
|
arXiv
|
code
Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. |
|
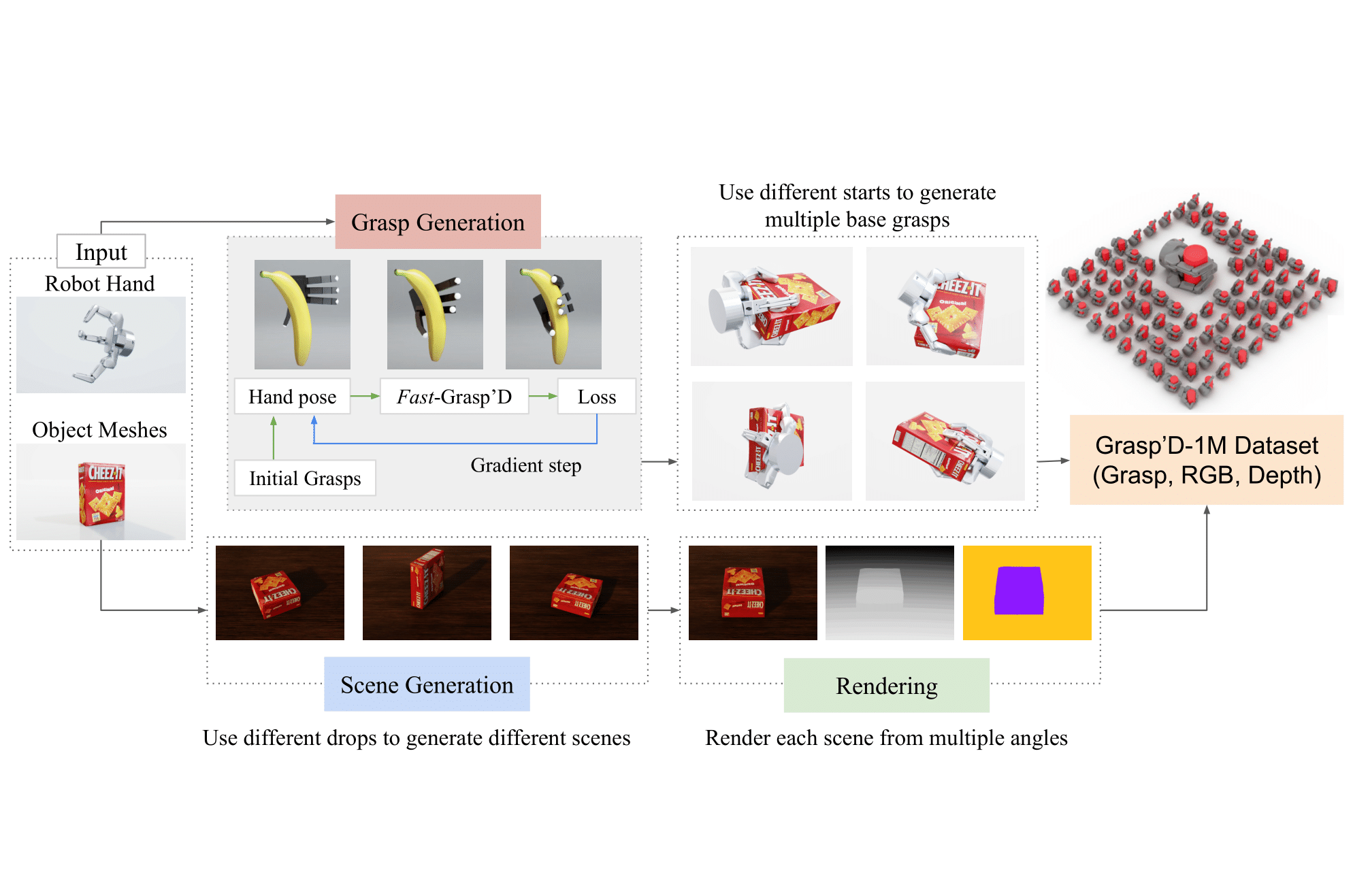
Fast-Grasp'D: Dexterous Multi-finger Grasp Generation Through
Differentiable Simulation
Dylan Turpin, Tao Zhong, Shutong Zhang, Guanglei Zhu, Jingzhou Liu, Ritvik Singh, Eric Heiden, Miles Macklin, Stavros Tsogkas, Sven Dickinson, Animesh Garg ICRA 2023
website
|
abstract
|
bibtex
|
arXiv
Multi-finger grasping relies on high quality training data, which is hard to obtain: human data is hard to transfer and synthetic data relies on simplifying assumptions that reduce grasp quality. By making grasp simulation differentiable, and contact dynamics amenable to gradient-based optimization, we accelerate the search for high-quality grasps with fewer limiting assumptions. We present Grasp’D-1M: a large-scale dataset for multi-finger robotic grasping, synthesized with Fast- Grasp’D, a novel differentiable grasping simulator. Grasp’D- 1M contains one million training examples for three robotic hands (three, four and five-fingered), each with multimodal visual inputs (RGB+depth+segmentation, available in mono and stereo). Grasp synthesis with Fast-Grasp’D is 10x faster than GraspIt! and 20x faster than the prior Grasp’D differentiable simulator. Generated grasps are more stable and contact-rich than GraspIt! grasps, regardless of the distance threshold used for contact generation. We validate the usefulness of our dataset by retraining an existing vision-based grasping pipeline on Grasp’D-1M, and showing a dramatic increase in model performance, predicting grasps with 30% more contact, a 33% higher epsilon metric, and 35% lower simulated displacement. |
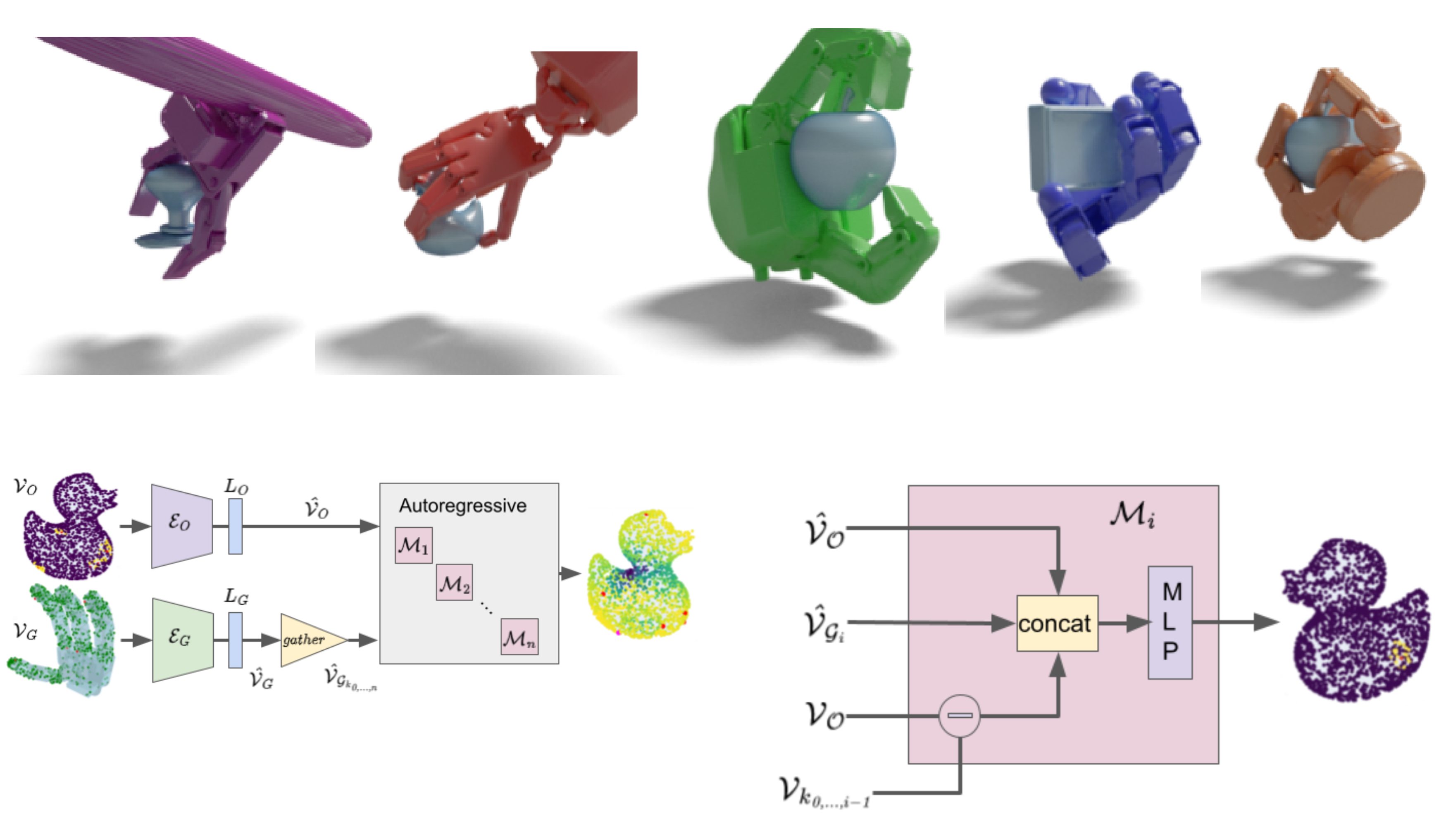
|
Geometry Matching for Multi-Embodiment Grasping.
Maria Attarian, Muhammad Adil Asif, Jingzhou Liu, Ruthrash Hari, Animesh Garg, Igor Gilitschenski, Jonathan Tompson CoRL 2023
website
|
abstract
|
bibtex
|
arXiv
|
code
Many existing learning-based grasping approaches concentrate on a single embodiment, provide limited generalization to higher DoF end-effectors and cannot capture a diverse set of grasp modes. We tackle the problem of grasping using multiple embodiments by learning rich geometric representations for both objects and end-effectors using Graph Neural Networks. Our novel method - GeoMatch - applies supervised learning on grasping data from multiple embodiments, learning end-to-end contact point likelihood maps as well as conditional autoregressive predictions of grasps keypoint-by-keypoint. We compare our method against baselines that support multiple embodiments. Our approach performs better across three end-effectors, while also producing diverse grasps. |

|
Orbit: A Unified Simulation Framework for Interactive Robot Learning
Environments
Mayank Mittal, Calvin Yu, Qinxi Yu, Jingzhou Liu, Nikita Rudin, David Hoeller, Jia Lin Yuan, Ritvik Singh, Yunrong Guo Hammad Mazhar, Ajay Mandlekar, Buck Babich, Gavriel State, Marco Hutter, Animesh Garg IROS 2023 | RA-L
website
|
abstract
|
bibtex
|
arXiv
|
code
We present Orbit, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and high-fidelity rigid and deformable body simulation. With Orbit, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. Orbit allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. |
Education |

|
Ph.D in Robotics
School of Computer Science Carnegie Mellon University |
2024 - Present |

|
Bachelor of Applied Science and Engineering
Engineering Science Robotics University of Toronto |
2019 - 2024 |
Personal Projects |

|
Safe Drone Teleoperation with Real Time Mapping and Obstacle
Avoidance
Engineering Science Robotics Capstone University of Toronto
website
|
abstract
|
video
|
code
Teleoperating a drone in a safe manner can be challenging, particularly in cluttered indoor environments with an abundance of obstacles. We present a safe teleoperation system for drones by performing automatic real-time dynamic obstacle avoidance, allowing us to expose a suite of simplified high-level control primitives to the drone operator such as "fly forward", "fly to the left", "fly up", "rotate", etc. This system reduces the complexity and the extent of the manual controls required from drone operators to fly the drone safely. The system accomplishes this by constructing a dynamic map of its environment in real-time and continuously performing path-planning using the map in order to execute a collision-free path to the desired user-specified position target. |
|
Modified template from here. |